 There are challenges with downloading genomic data. File sizes are large, and it can be time consuming to retrieve multiple files. Sometimes downloads fail. A custom script may be required. Fortunately, a solution to all of these frustrations is now available—NCBI Datasets.
There are challenges with downloading genomic data. File sizes are large, and it can be time consuming to retrieve multiple files. Sometimes downloads fail. A custom script may be required. Fortunately, a solution to all of these frustrations is now available—NCBI Datasets.
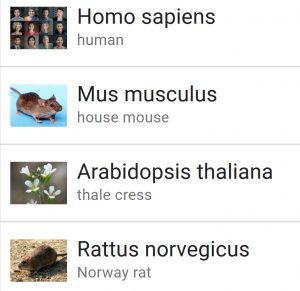
This experimental resource allows users to easily download eukaryotic genome sequence and annotation data by assembly accession, taxonomic name (scientific and common), or taxonomy ID. The web interface allows for browsing by organism, with the most common experimental species conveniently available from the main page. For example, try selecting the house mouse (mus musculus), then select all 22 associated assemblies. Options for the type of data for the download include genomic, transcript, and protein sequences as well as annotation features. Continue reading →

 In July 2019, NIH and Figshare announced the one-year pilot launch of a general data repository for all NIH-funded researchers:
In July 2019, NIH and Figshare announced the one-year pilot launch of a general data repository for all NIH-funded researchers: 