Data journals are a means to share datasets and communicate detailed information about the methods and instrumentation used to acquire the data.
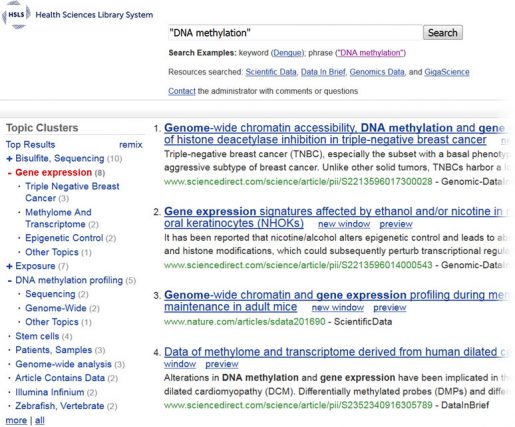
However, locating datasets shared via these publications can be challenging, as PubMed includes very few data journals and does not provide full-text searching to easily locate information not found in the title or abstract of an article. To facilitate this discovery, HSLS created a federated search portal named search.DataJournals, which searches the full text of four open access data journals: Data in Brief, Genomics Data, GigaScience, and Scientific Data.
A query will search across all fields of the data article including data description, materials, methods, instrumentation, data source location, and data accessibility. Search results are aggregated and ordered by relevance and can be filtered by clustered topical categories that are created on the fly based on the textual information of the retrieved records.
Contact HSLS Data Services if you have questions about using this tool, locating datasets, or sharing data.
~Melissa Ratajeski
 Join the librarians at the University of Pittsburgh in celebrating
Join the librarians at the University of Pittsburgh in celebrating 
 What is an electronic lab notebook (ELN), and why use one? Quite simply, ELNs are designed to replace paper lab notebooks that can be damaged, misplaced, or potentially altered. The digital nature of ELNs allows for:
What is an electronic lab notebook (ELN), and why use one? Quite simply, ELNs are designed to replace paper lab notebooks that can be damaged, misplaced, or potentially altered. The digital nature of ELNs allows for: