You already conduct literature searches with PubMed and you read free full-text articles from PubMed Central (PMC), so why try Europe PMC? Quite simply, because your current search strategy might not be finding all of the relevant information.
Europe PMC contains over 5 million more abstracts than PubMed. That’s 5 MILLION! This repository provides a single search not only of abstracts and full-text articles, but also biological patents, NHS clinical guidelines, preprints, and more. For useful information and tips on performing searches, see Help using Europe PMC.
Three specific features of note within Europe PMC are: (1) preprint searching, (2) linking to public gene, protein, and chemical compound databases directly from articles, and (3) article annotations via text mining.
- Preprints
Preprints are non-peer reviewed articles posted to preprint servers that promote the rapid communication of research data. Europe PMC began indexing preprints in July 2018 to improve the discoverability of the data reported in preprints, and facilitate inclusion in grant reports, article citations, and credit/attribution. Indexed preprints have a DOI and are retrievable via Crossref metadata services. Initial included preprint servers are: bioRxiv, PeerJ Preprints, ChemRxiv, F1000Res, and more. Europe PMC clearly labels preprints with a PPR ID on both the abstract view and search results, and crosslinks any subsequent peer-reviewed publications.
- Data Links/Citations
When an article indexed by Europe PMC refers to associated data, a link(s) to the data is provided within the results page (see figure below). Searches may be limited to include only a specific type of data by using the Advanced Search form, which identifies articles that cite database records mined from the full text. Initial cross referenced databases include: BioSamples, ClinicalTrials.gov, Ensembl, Gene Ontology, OMIM, PDB, RefSeq, UniProt, and more.
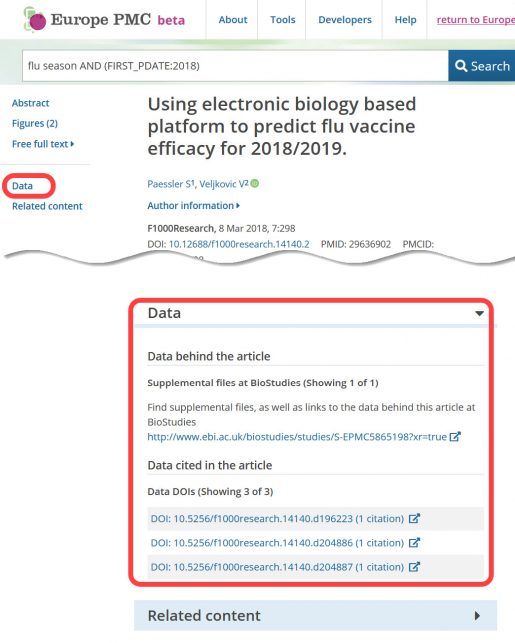
- SciLite Annotations
SciLite allows biological terms (e.g., diseases, chemicals, protein interactions) identified by text mining algorithms to be highlighted on abstracts and full text articles. This makes it easier for readers to quickly scan an article and get an overview, find key concepts, and discover evidence such as gene-disease associations or molecular interactions. See the figure below for an example.

~ Carrie Iwema